
type
status
date
slug
summary
tags
category
icon
password
一、概述
1.1、什么是Netty
Netty是一个异步的、基于事件驱动的网络应用驱动框架,用于快速开发可维护、高性能的网络服务器和客户端。
- Netty底层IO模型可以随意切换,比如从NIO切换到BIO,但一般很少会如此做。
- Netty自带拆包解包,从NIO繁琐复杂的细节中解放出来,让开发者重点关系业务逻辑。
- 对
Selector做了很多细小的优化,reactor线程模型能做到高效的并发处理。
1.2、Netty与Tomcat的区别?
两者最大的区别在于
通信协议,Tomcat是基于Http协议的一个Web容器。但是Netty不一样,它可以通过编程自定义各种协议,原因是Netty可以编码/解码字节流,完成类似redis访问的功能。1.3、Netty为什么并发高?
首先Netty是基于NIO(非阻塞IO)开发的网络通信框架,相对于BIO(阻塞IO),并发性能是得到了非常高的提升。
阻塞IO通信方式与非阻塞通信方式的区别
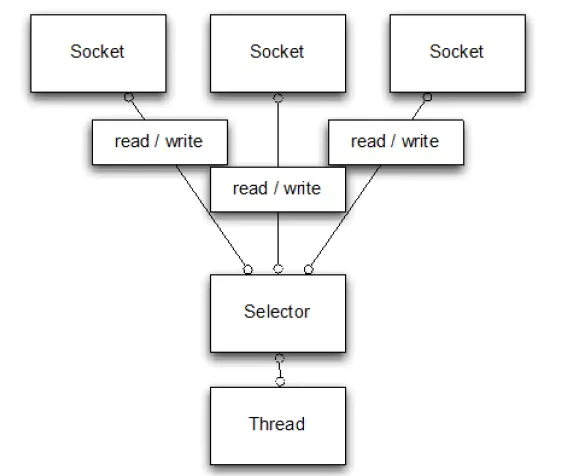
两者最明显的区别是非阻塞IO通信方式中的
Selector,当一个连接建立后,首先是接收客户端发过来的全部数据,然后是服务端处理完请求业务之后返回response(响应数据)给客户端。在BIO中,等待客户端发送数据这个过程是阻塞的,也就是一个线程只能处理一个请求的情况,且机器支持的最大线程是有限的,这就是BIO为什么不支持高并发的原因。而NIO中,当一个Socket建立好之后,Thread并不会阻塞去接收这个Socket,而是将这个请求交给Selector,Selector会不断的去遍历所有的Socket,一旦有一个Socket建立完成,就会通知Thread,然后Thread处理完数据再返回给客户端,这个过程是不阻塞的,如此就能让一个Thread处理更多的请求了。
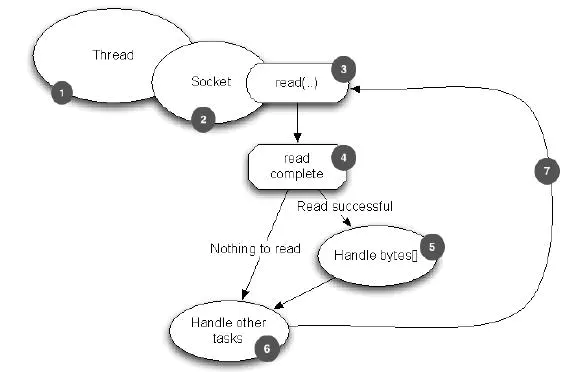
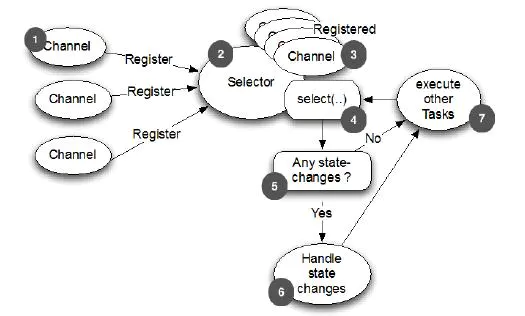
- BIO,同步阻塞IO:阻塞整个步骤,如果连接少,他的延迟是最低的,因为一个线程只处理一个连接,适用于少连接且延迟低的场景,比如说数据库连接。
- NIO,同步非阻塞IO:阻塞业务处理但不阻塞数据接收,适用于高并发且处理简单的场景,比如聊天软件。
- 多路复用IO:他的两个步骤处理是分开的,也就是说,一个连接可能他的数据接收是线程a完成的,数据处理是线程b完成的,他比BIO能处理更多请求。
- 信号驱动IO:这种IO模型主要用在嵌入式开发,不参与讨论。
- 异步IO:他的数据请求和数据处理都是异步的,数据请求一次返回一次,适用于长连接的业务场景。
1.4、Netty为什么传输快?
Netty传输快主要是依赖NIO的一个特性——零拷贝。Java的内存有堆内存、栈内存和字符串常量池等,其中堆内存是占用内存空间最大的一块,也是Java对象存放的地方。一般数据如果需要从IO读取到堆内存,中间需要经过Socket缓冲区,一个数据需要拷贝两次才能到达他的终点,在数据量大的情况下,会造成不必要的资源浪费。Netty的零拷贝特性,是在需要接收数据的时候,会在堆内存之外开辟一块内存,数据就直接从IO读到了那块内存中,在Netty里面通过
ByteBuf可以对这些数据进行直接操作,从而加快了传输速度。二、Hello World
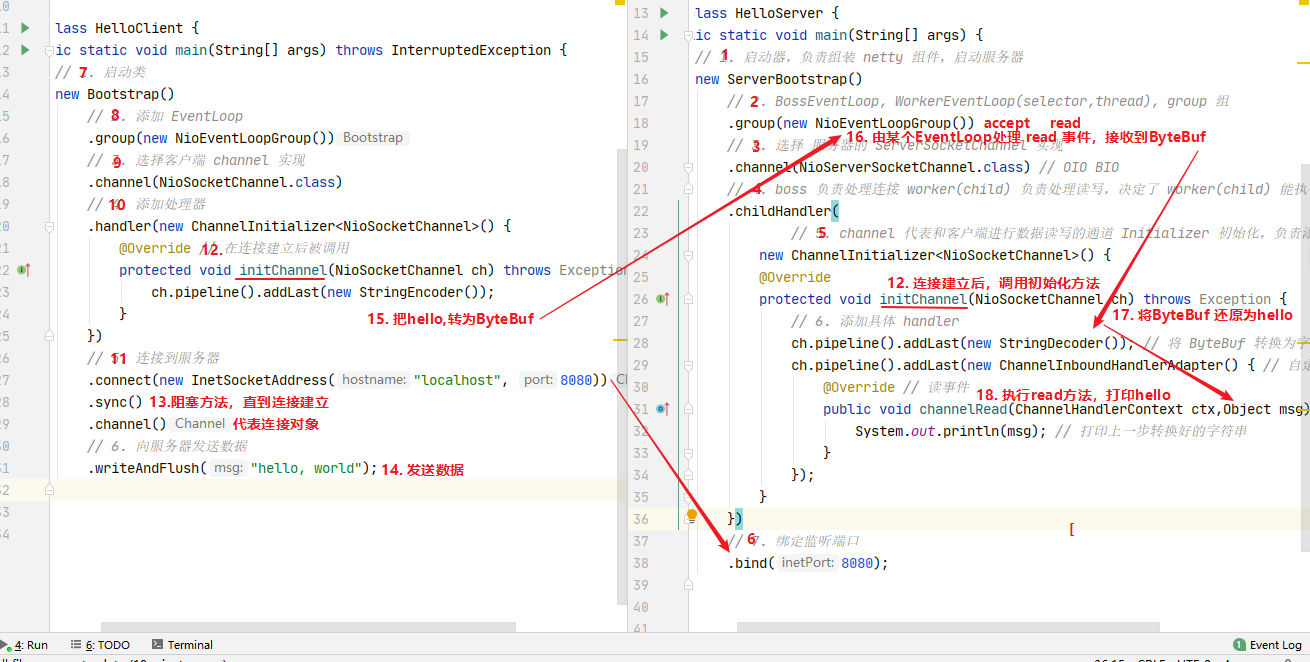
2.1、服务器端
2.2、客户端
2.3、流程梳理
💡 提示
一开始需要树立正确的观念
- 把 channel 理解为数据的通道
- 把 msg 理解为流动的数据,最开始输入是 ByteBuf,但经过 pipeline 的加工,会变成其它类型对象,最后输出又变成 ByteBuf
- 把 handler 理解为数据的处理工序
- 工序有多道,合在一起就是 pipeline,pipeline 负责发布事件(读、读取完成...)传播给每个 handler, handler 对自己感兴趣的事件进行处理(重写了相应事件处理方法)
- handler 分 Inbound 和 Outbound 两类
- 把 eventLoop 理解为处理数据的工人
- 工人可以管理多个 channel 的 io 操作,并且一旦工人负责了某个 channel,就要负责到底(绑定)
- 工人既可以执行 io 操作,也可以进行任务处理,每位工人有任务队列,队列里可以堆放多个 channel 的待处理任务,任务分为普通任务、定时任务
- 工人按照 pipeline 顺序,依次按照 handler 的规划(代码)处理数据,可以为每道工序指定不同的工人
三、组件
3.1、EventLoop(事件循环对象)
EventLoop本质上是一个单线程执行器(在内部维护了一个线程和Selector),线程的run()方法来处理Channel上的IO事件。继承关系:
- 一个是JUC里的
ScheduledExecutorService,因此包含了线程池中所有的方法。
- 一个是Netty自己提供的
OrderedEventExecutor,其中两个重要方法: Boolean inEventLoop(Thread t)用于判断一个线程是否属于此EventLoop。EventLoopGroup parent()用于查看自己属于哪个EventLoopGroup
EventLoopGroup是一组EventLoop,Channel会调用EventLoopGroup的register方法来绑定其中一个EventLoop,后续这个Channel上的所有IO事件都会由此EventLoop来处理(也就是单线程处理,保证IO事件处理时的线程安全问题)
- 另一个是Netty自己提供的EventExecutorGroup,该接口实现了Iterable迭代器接口,能够遍历EventLoop,同时也提供了next方法能够获取集合中的下一个EventLoop。
EventLoopGroup(事件循环组)
事件循环组可以理解为一个线程池,里面包含多个事件循环线程(EventLoop),在初始化事件循环组的时候可以指定创建事件循环个数。每个EventLoop绑定了一个任务队列,用于处理非IO事件,比如通道注册、端口绑定等。事件循环组中的EventLoop线程均处于活跃状态,每个EventLoop线程绑定一个选择器(Selector),一个选择器(Selector)注册了多个通道(客户端连接),当通道产生事件的时候,绑定在选择器上的事件循环线程就会激活,并处理事件。
对于BossGroup事件循环组来说,里面的事件循环线程只监听通道的连接事件(即accept)。而WorkerGroup事件循环组中的事件循环线程处理读写事件。当监听到通道的连接事件(accept),会交给BossGroup中的事件循环线程来处理,处理完后生成客户端(channel)注册至WorkerGroup中的某个事件循环,并绑定事件,该线程就会监听事件,当客户端发起读写请求的时候,该事件循环就会监听到并处理。
NioEventLoop处理IO事件
其中ctx.fireChannelRead(msg)方法逻辑
💡 handler 执行中如何换人?
关键代码
io.netty.channel.AbstractChannelHandlerContext#invokeChannelRead()- 如果两个 handler 绑定的是同一个线程,那么就直接调用
- 否则,把要调用的代码封装为一个任务对象,由下一个 handler 的线程来调用
EventLoop执行普通任务
可用来执行耗时较长的任务
EventLoop执行定时任务
3.2、Channel && ChannelFuture
Channel
close():关闭channel
closeFuture():返回一个CloseFuture对象,可以基于sync()方法或者addListener()方法实现在Channel的关闭之后执行指定逻辑
pipeline():用于添加handle处理器
write():用于将数据写出但不刷出,数据是暂时存储在缓冲区中,执行flush()方法可将数据刷出
writeAndFlush():用于将数据写出并刷出
ChannelFuture
继承了JUC下的Future接口,拥有异步返回结果的能力,是异步Channel IO操作的结果,Netty中的所有IO操作都是异步的。
主要方法:
addListener(GenericFutureListener):用于在ChannelFuture上添加一个listener,在 IO 操作完成时收到通知。建议尽可能首选 addListener(GenericFutureListener) 而不是 await(),以便在 IO 操作完成时获得通知并执行任何后续任务。 addListener(GenericFutureListener) 是非阻塞的。它只是简单地将指定的 ChannelFutureListener 添加到 ChannelFuture 中,当与 future 相关的 IO 操作完成时,IO 线程会通知监听器。
await():await() 是一个阻塞操作,一旦被调用,调用者线程就会阻塞,直到操作完成。注意不要在 ChannelHandler 内部调用 await() 方法,因为ChannelHandler 中的事件处理方法通常由 IO 线程调用,如果 await() 被 IO 线程调用的事件处理方法调用,它正在等待的 IO 操作可能永远不会完成,因为 await() 会阻塞它正在等待的 IO 操作,这是一个死锁。
sync():同步阻塞方法,让调用者线程同步等待,直到NIO线程连接建立后才会执行;
异步提升的是什么?
思考下面的场景,4 个医生给人看病,每个病人花费 20 分钟,而且医生看病的过程中是以病人为单位的,一个病人看完了,才能看下一个病人。假设病人源源不断地来,可以计算一下 4 个医生一天工作 8 小时,处理的病人总数是:
4 * 8 * 3 = 96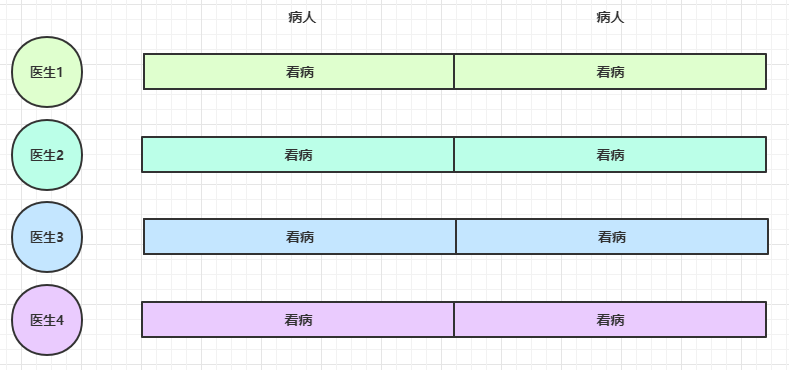
经研究发现,看病可以细分为四个步骤,经拆分后每个步骤需要 5 分钟,如下
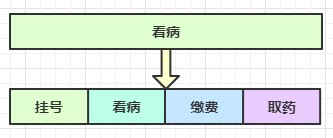
因此可以做如下优化,只有一开始,医生 2、3、4 分别要等待 5、10、15 分钟才能执行工作,但只要后续病人源源不断地来,他们就能够满负荷工作,并且处理病人的能力提高到了
4 * 8 * 12 效率几乎是原来的四倍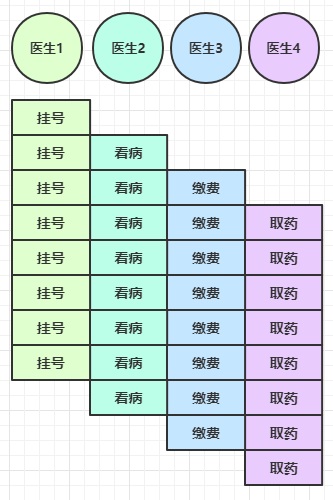
要点
- 单线程没法异步提高效率,必须配合多线程、多核 cpu 才能发挥异步的优势
- 异步并没有缩短响应时间,反而有所增加
- 合理进行任务拆分,也是利用异步的关键
3.3、Future && Promise
在异步处理时经常会用到这两个接口,Netty中的Future继承自JDK中的Future,而Promise又对Netty自己的Future进行了扩展。
- JDK中的Future只能同步等待任务结束(或成功、或失败)才能得到结果,而Netty中的Future可以同步等待任务结束得到结果,也可以异步方式得到结果,但都是要等任务结束。
- Netty中的Promise不仅有Future的功能,还脱离了任务独立存在,只作为两个线程间传递结果的容器,可以主动创建,并设置结果和失败异常原因等功能。
能/名称 | jdk Future | netty Future | Promise |
cancel | 取消任务 | - | - |
isCanceled | 任务是否取消 | - | - |
isDone | 任务是否完成,不能区分成功失败 | - | - |
get | 获取任务结果,阻塞等待 | - | - |
getNow | - | 获取任务结果,非阻塞,还未产生结果时返回 null | - |
await | - | 等待任务结束,如果任务失败,不会抛异常,而是通过 isSuccess 判断 | - |
sync | - | 等待任务结束,如果任务失败,抛出异常 | - |
isSuccess | - | 判断任务是否成功 | - |
cause | - | 获取失败信息,非阻塞,如果没有失败,返回null | - |
addLinstener | - | 添加回调,异步接收结果 | - |
setSuccess | - | - | 设置成功结果 |
setFailure | - | - | 设置失败结果 |
Netty中的Future
输出
Promise
3.4、Handler && PipeLine
ChannelHandler用来处理 Channel上的各种事件,分为入站、出站两种。所有的 ChannelHandler被连成一串就是PipeLine。- 入站处理器通常是 ChannelInboundHandlerAdapter 的子类,主要用来读取客户端数据,写回结果。
- 出战处理器通常是 ChannelOutboundHandlerAdapter 的子类,主要用来对写回结果进行加工。
每个Channel是一个产品的加工车间,PipeLine是车间中的流水线,ChannelHandler就是流水线上的各道工序,ByteBuf是原材料,原材料经过很多工序的加工:先经过一道道入站工序,再经过一道道出站工序最终变成产品。
服务端
客户端
输出
以上,ChannelInboundHandlerAdapter 是按照addLast()的顺序执行的,而ChannelOutboundHandlerAdapter是按照addLast()的逆序执行的。ChannelPipeLine 的实现是一个 ChannelHandlerContext(包装了ChannelHandler)组成的双向链表。

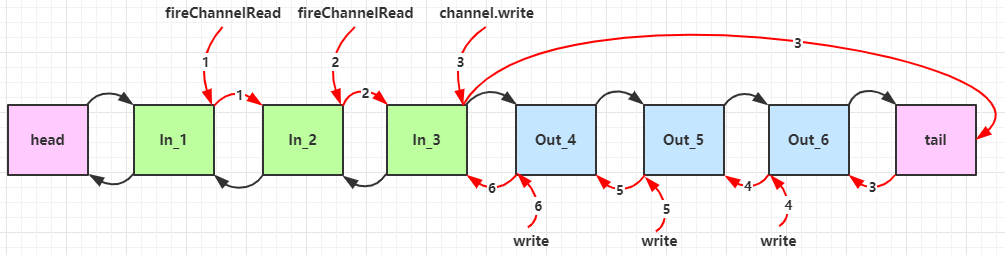
- 入站处理器中,ctx.fireChannelRead(msg) 是 调用下一个入站处理器
- 如果注释掉 1 处代码,则仅会打印 1
- 如果注释掉 2 处代码,则仅会打印 1 2
- 3 处的 ctx.channel().write(msg) 会 从尾部开始触发 后续出站处理器的执行
- 如果注释掉 3 处代码,则仅会打印 1 2 3
- 类似的,出站处理器中,ctx.write(msg, promise) 的调用也会 触发上一个出站处理器
- 如果注释掉 6 处代码,则仅会打印 1 2 3 6
- ctx.channel().write(msg) vs ctx.write(msg)
- 都是触发出站处理器的执行
- ctx.channel().write(msg) 从尾部开始查找出站处理器
- ctx.write(msg) 是从当前节点找上一个出站处理器
- 3 处的 ctx.channel().write(msg) 如果改为 ctx.write(msg) 仅会打印 1 2 3,因为节点3 之前没有其它出站处理器了
- 6 处的 ctx.write(msg, promise) 如果改为 ctx.channel().write(msg) 会打印 1 2 3 6 6 6... 因为 ctx.channel().write() 是从尾部开始查找,结果又是节点6 自己
图1 - 服务端 pipeline 触发的原始流程,图中数字代表了处理步骤的先后次序
3.5、ByteBuf
网络数据的基本单位是字节,
ByteBuf是netty的Server与Client之间通信的数据传输载体(Netty的数据容器),也是对NIO的ByteBuffer进一步的封装。ByteBuffer的缺点:
ByteBuffer长度固定,一旦分配完成,容量不能动态扩展和收缩,当需要编码的POJO对象大于ByteBuffer的容量时,会发送索引越界异常。
ByteBuffer只有一个标识位置的指针position,读写的时候需要手工调用filp()和rewind(),使用者需谨慎处理API。
ByteBuffer的API功能有限,一些高级和实用的特性并不支持,需要使用者自己编程实现。
ByteBuf的优点:
- 通过内置的复合缓冲区类型实现了透明的零拷贝。
- 容量按需增长。
- 读写模式切换不要调用
file()方法。
- 读写两种模式使用了不同的索引。
- 支持引用计数。
- 支持池化。
1、创建
2、直接内存 vs 堆内存
创建池化基于堆的 ByteBuf
创建池化基于直接内存的 ByteBuf
- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用。
- 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放。
3、池化 vs 非池化
池化的最大意义在于可以
重用 ByteBuf,优点有- 没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
- 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
池化功能是否开启,可以通过下面的系统环境变量来设置
- 4.1 以后,非 Android 平台默认启用池化实现,Android 平台启用非池化实现
- 4.1 之前,池化功能还不成熟,默认是非池化实现
4、扩容
再写入一个 int 整数时,容量不够了(初始容量是 10),这时会引发扩容
扩容规则是
- 如何写入后数据大小未超过 512,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后 capacity 是 16
- 如果写入后数据大小超过 512,则选择下一个 2^n,例如写入后大小为 513,则扩容后 capacity 是 2^10=1024(2^9=512 已经不够了)
- 扩容不能超过 max capacity 会报错
结果是
- Author:拾荒😂
- URL:https://blog.zhulinz.top//article/netty02
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!